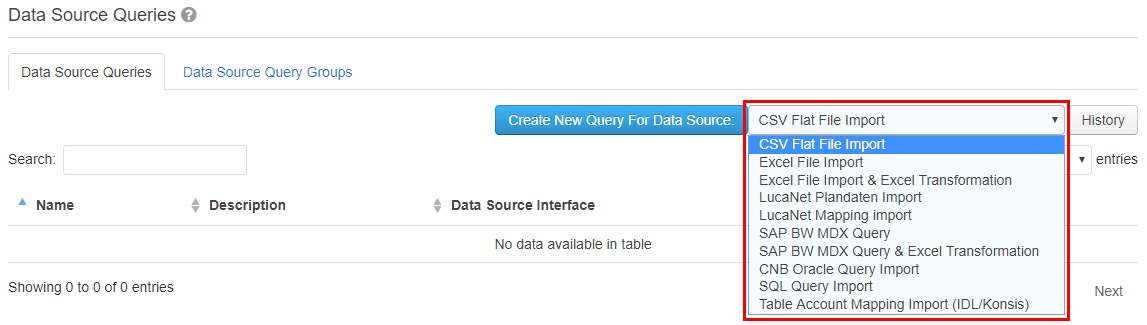
Eine neue Datenquellenabfrage kann über den Menüpunkt „Stammdaten > Datenquellenabfragen“ angelegt werden. Auf der Reiterkarte „Datenquellenabfragen“ muss zuerst die Art der Quelle ausgewählt werden. Dies geschieht über die Drop-Down-Liste neben den Knopf „Neue Abfrage anlegen für Datenquelle“. 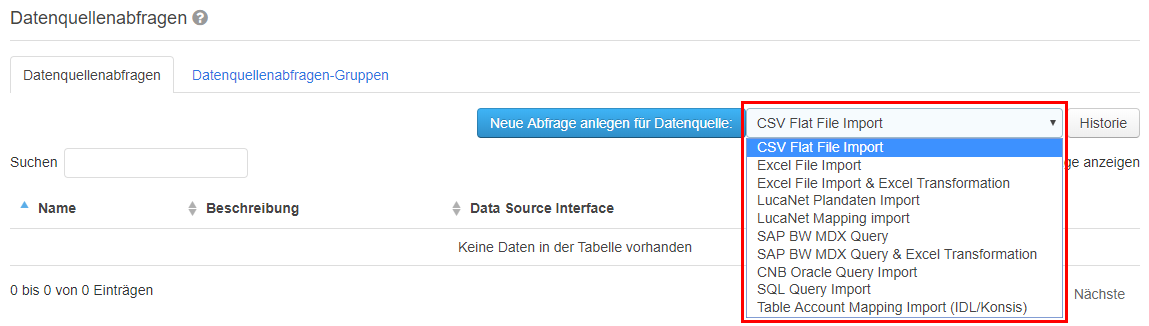 Image Added Image Added
Folgende Datenquellen stehen dabei zur Auswahl: - CSV Flat File: Eine CSV-Datei, die vor dem Ausführen der Abfrage hochgeladen wird.
- Excel File: Eine Excel-Datei, die vor dem Ausführen der Abfrage hochgeladen wird.
- Excel File & Excel Transformation: Eine Excel-Datei, die vor dem Ausführen der Abfrage hochgeladen wird. Zudem wurde eine Excel-Datei mit Formeln hinterlegt, die die Werte aus der Datenquelle anpasst.
- LucaNet Plandaten:
- LucaNet Mapping:
- SAP BW MDX Query:
- SAP BW MDX Query & Excel Transformation:
- Oracle Query:
- SQL Query:
- Table Account Mapping (IDL/Konsis):
Zur Konfiguration einer Datenquellenabfragen sind allgemeine sowie für die Datenquelle spezifische Parameter zu konfigurieren. Zudem muss das Format der vorliegenden Daten, der sogenannte „Mapping Type“, angegeben werden. Allgemeine ParameterUnabhängig von der ausgewählten Datenquelle und dem ausgewählten Mapping Type gibt es Parameter, die für jede Datenquellenabfrage konfiguriert werden muss. - Name: Der Name der Datenquellenabfrage. Dieser Name taucht in der Liste der verfügbaren Datenquellenabfragen auf, wenn man eine neue Meldung über einen Datenimport generiert.
- Beschreibung: Eine Beschreibung der Datenquellenabfrage. Dieser Parameter ist optional.
Persönliche Abfrage: Ist diese Option aktiv, ist diese Datenquellenabfrage nur für den Benutzer sichtbar, der die Abfrage angelegt hat. Andernfalls ist die Datenquellenabfrage für jeden angemeldeten Anwender sichtbar. | Format der Koordinaten in der Datenquelle | Vorzunehmende Konfiguration für „Nutze numerische Codes“ |
|---|
| 10 für den Koordinatencode "0010" | aktivieren | | 0010 für den Koordinatencode "0010" | nicht aktivieren |
- Währungsspalte: Für einige XBRL-Meldungen müssen Werte in verschiedenen Währungen berichtet werden. Wenn die Währung der Werte in der Datenquelle mit enthalten ist, kann hier angegeben werden, in welcher Spalte sich die Währungsinformation befindet. Der Spaltenindex ist nullbasiert. Das bedeutet, dass die 1. Spalte der Datenquelle den Index 0 hat. Falls sich die Währung also in der 5. Spalte der Datenquelle befindet, ist hier 4 anzugeben.
- Nullwerte importieren: In XBRL ist das Melden des Wertes 0 für eine Zelle nicht gleichbedeutend mit dem nicht-Melden eines Wertes für eine Zelle. Während das nicht-Melden eines Wertes ausdrückt, dass ein Sachverhalt nicht anwendbar ist, bedeutet das Melden des Wertes 0, dass dieser Sachverhalt anwendbar ist, doch der Wert für diesen Sachverhalt gleich 0 ist. Über diese Option ist es deshalb möglich Daten nicht zu importieren, wenn deren Wert 0 beträgt.
Prozentwerte durch 100 teilen: In XBRL werden Prozentwerte als Kommazahlen berichtet. Um 55% zu berichten wird erwartet, dass der Wert 0.55 in die XBRL-Datei geschrieben wird. Abhängig davon, in welchem Format Prozentwerte in der Datenquelle vorliegen, müssen diese ggf. durch 100 geteilt werden. | Format der Prozentwerte in der Datenquelle | Vorzunehmende Konfiguration für „Prozentwerte durch 100 teilen“ |
|---|
| 55 für den Wert 55% | aktivieren | | 0.55 für den Wert 55% | nicht aktivieren |
- Ersetze # in Z-Achsen-Spalte: Einige Datenquellen geben den Wert # zurück, falls kein Wert für eine bestimmte Information vorhanden ist. Dies kann bei der Angabe der Z-Achse zu ungewünschten Effekten führen. Deshalb ist es möglich über diese Option sämtliche #-Zeichen in der Z-Achsen-Spalte zu entfernen.
Mapping TypeAbhängig von Art und Format der Daten in der Quelle muss ein bestimmter Mapping Type ausgewählt werden. Abhängig vom Mapping Type sind weitere Konfigurationen vorzunehmen. Folgende Typen sind auswählbar: - Table FRD Mapping: In diesem Format ist der Inhalt der Datenquelle tabellarisch aufgebaut. In jeder Zeile befindet sich dabei der Wert einer Zelle zusammen mit den Koordinaten der Zelle in jeweils separaten Spalten.
- Table BLOB Mapping: Die Daten der Quelle entspricht dem Format eines einzelnen Meldebögen. Die Anzahl der Zeilen und Spalten innerhalb der Quelldatei entspricht der Anzahl der Zeilen und Spalten innerhalb des Meldebogens.
- Concept Mapping: Nicht alle Taxonomien definieren tabellarische Meldebögen. Importierte Werte können daher nicht über Zellkoordinaten einer Taxonomiepositionen zugeordnet werden. In diesen Fällen kann das Mapping alternativ über den technischen Namen von Taxonomiepositionen durchgeführt werden. Eine Taxonomieposition ist dabei eine zu berichtende Metrik, In der Datenquelle befindet sich somit in jeder Zeile ein zu berichtender Wert sowie der technischer Name der dazugehörigen
- Simple Concept Mapping:
- Filing Indicators: Dieser Typ wird ausgewählt, wenn keine Werte für einen Meldebogen importiert werden sollen, sondern Werte für Filing Indiators. Ein Filing Indicator gibt an, ob ein bestimmter Meldebogen berichtet wurde oder nicht. Die Datenquelle besitzt also eine Spalte, in der sich die ID des Filing Indicators befindet sowie eine Spalte mit einem Wahrheitswert, true oder false, abhängig davon, welcher Wert in den Filing Indicator geschrieben werden soll.
Beispiele für Datenformate der einzelnen Mapping Types befinden sich in den jeweiligen nachfolgenden Unterkapiteln. Table FRD MappingBeim Table FRD Mapping befindet sich jeder zu berichtender Wert in einer separaten Zeile. Desweiteren befinden sich in separaten Spalten die Koordinaten der Zelle, in der der Wert eingetragen werden soll, also Tabelle, Zeile, Spalte und Z-Achse. | Tabelle | Zeile | Spalte | Z-Achse / Seite | Wert |
|---|
| C_01.01 | 010 | 010 |
| 1000000 | | C_01.01 | 015 | 010 |
| 500000 | | C_07.00.a | 010 | 010 | 001 | 100000 | | C_07.00.a | 010 | 010 | 002 | 50000 |
Über die Parameter wird konfiguriert, in welcher Spalte sich welche Information befindet. Der Spaltenindex ist nullbasiert. Das bedeutet, dass die 1. Spalte der Datenquelle den Index 0 hat, die 2. Spalte den Index 1 usw. Folgende Parameter können konfiguriert werden: - Tabellen-Id Spalte: Die Spalte, in der sich die technische ID der Tabelle befindet. Die ID ist üblicherweise die Kennzeichnung des Meldebogens, wobei das Leerzeichen durch ein Unterstrich ersetzt wird. Die IDs der Meldebögen kann auch aus dem ersten Tabellenblatt der Excel-Visualisierung der Taxonomie entnommen werden, welche unter dem Menüpunkt „Taxonomien“ heruntergeladen werden können.
- Spalten-Code Spalte: Die Spalte, in der sich der Koordinatencode der Spalte befindet. Die Koordinatencodes können ebenfalls der Excel-Visualisierung der Taxonomie entnommen werden.
- Zeilen-Code Spalte: Die Spalte, in der sich der Koordinatencode der Zeile befindet.
- Z-Achsen Spalte: Die Spalte, in der sich der Koordinatencode der Z-Achse befindet.
- Wert-Spalte: Die Spalte, in der sich der Wert der Zelle befindet.
Nutze numerische Codes: XBRL-Taxonomien definieren, wie die Meldeformulare aussehen, die berichtet werden müssen. Die meisten Taxonomien definieren zudem Koordinatencodes für einzelne Zeilen, Spalten und Z-Achsen. Diese Koordinatencodes können verwendet werden um die einzelnen importierten Daten einer Zelle zuzuweisen. Oftmals handelt es sich bei den Koordinatencodes um Ziffernfolgen, wie „0010“. Abhängig vom Format der Koordinaten in der Datenquelle muss diese Option entsprechend konfiguriert werden. | Format der Koordinaten in der Datenquelle | Vorzunehmende Konfiguration für „Nutze numerische Codes“ |
|---|
| 10 für den Koordinatencode „0010“ | aktivieren | | 0010 für den Koordinatencode „0010“ | nicht aktivieren |
- Unvollständige Tabellen-Ids verwenden: In Solvency II Taxonomien bestehen Tabellen-IDs in der Regel aus einer Kombination von Buchstaben und 4 zweistelligen Zahlenkombination, jeweils getrennt durch einen Punkt, wie z.B. S.03.01.01.01 und S.03.01.01.02. Falls in der Datenquelle die letzte Zahlenkombination fehlt, ist diese Option zu aktivieren. Es wird dann versucht die passende Zelle mit dieser unvollständigen Tabellen-ID zu ermitteln.
- Standard-Z-Achse automatisch setzen: Wenn diese Option aktiviert wird, muss in der Quelle keine Z-Achse angegeben werden, wenn in der Taxonomie für die Tabelle nur eine Ausprägung für die Z-Achse vorhanden ist. Dies ist beispielsweise in Solvency II Taxonomie der Fall, wo einige Tabellen die Z-Achse „Sheets“ besitzen, die lediglich die Ausprägung „Z Axis:“ besitzt. Ist diese Option deaktiviert, ist für jede Zelle die Z-Achse „Z Axis:“ anzugeben. Ist diese Option aktiviert, ist diese Z-Achse nicht anzugeben.
- Zeige Nachrichten für Mappings mit leeren Werten: Nachdem ein Filing über eine Datenquellenabfrage erstellt wurde, werden in den Meldungsdetails angezeigt, ob die generierte Meldung XBRL valide ist. Über einen Button lassen sich die Validierungsmeldungen in einem Dialog anzeigen. In diesem Dialog befindet sich auch die Reiterkarte „Information“ mit einer Liste von Informationsmeldungen. Am Ende der Liste befinden sich auch Informationen zu den ausgeführten Datenquellenabfragen. Falls gewünscht, kann in der Liste auch eine Nachricht für jeden Datensatz angezeigt werden, für den kein Wert oder keine Tabellen-ID angegeben wurde.
 Image Added Image Added - Use Technical Z Axis Names: Z-Achsen können in der Quelle auf zwei Weisen referenziert werden: über ihren RC-Code oder über den technischen Namen der Achse, der in der Taxonomie definiert wurde. Ist diese Einstellung aktiv, wird der technische Name verwendet, ansonsten der RC-Code.
Table Blob MappingEin Blob ist eine Datenquelle, in dem die Daten genauso angeordnet werden wie im XBRL-Reporttemplate. Wenn also beispielsweise eine CSV-Datei als Datenquelle für eine Tabelle dient, welche aus 10 Zeilen und 3 Spalten besteht in denen Werte eingetragen werden können, dann muss die CSV-Datei ebenfalls aus 10 Zeilen und 3 Spalten bestehen. Die Datenquelle muss somit ein Abbild der XBRL-Tabelle darstellen. Bei offenen Tabellen, wie die Asset-Liste der Solvency II Taxonomie, in der beliebig viele Zeilen hinzugefügt werden können, müssen lediglich die Anzahl der Spalten übereinstimmen, da die Anzahl der Zeilen variabel sein kann. Folgende Parameter können für Blob Datenquellen konfiguriert werden: - Blob-Tabellen-Id: Die ID der XBRL-Tabelle, die über die Datenquelle importiert wird. Über eine einzelne Blob-Datenquelle können nur Daten für eine einzige Tabelle importiert werden.
- Transpornierte Blob-Tabelle: Wird diese Option ausgewählt, werden Zeilen und Spalten der Datenquelle vertauscht.
Concept Mapping
Simple Concept Mapping
Filing Indicators
Datenquellenspezifische ParameterCSV Flat File
Excel File
LucaNet Plandaten
LucaNet Mapping
SAP BW MDX Query
Oracle Query
SQL Query
Table Account Mapping (IDL/Konsis)
Um eine neue Datenquellenabfrage anzulegen, wählen Sie den Menüpunkt "Stammdaten > Datenquellenabfragen", den Tab „Datenquellenabfragen" Menüpunkt aus. Auf dieser Seite wählen Sie die Reiterkarte „Datenquellenabfragen“ aus und klicken Sie anschließend auf den Button „Neue Abfrage anlegen für Datenquelle:". Die Datenquelle wird “, nachdem Sie aus der Drop-downDown-Liste rechts von neben dem Button die Datenquelle ausgewählt haben. 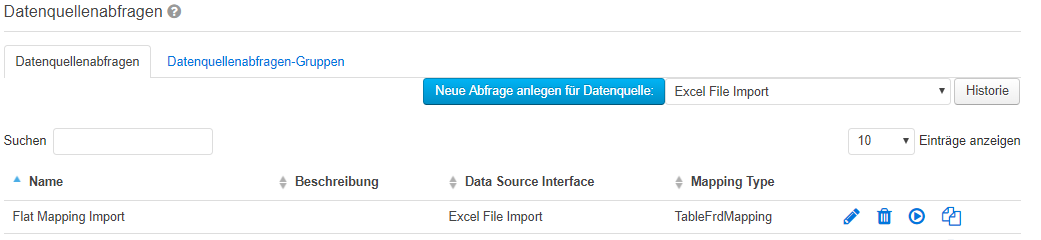
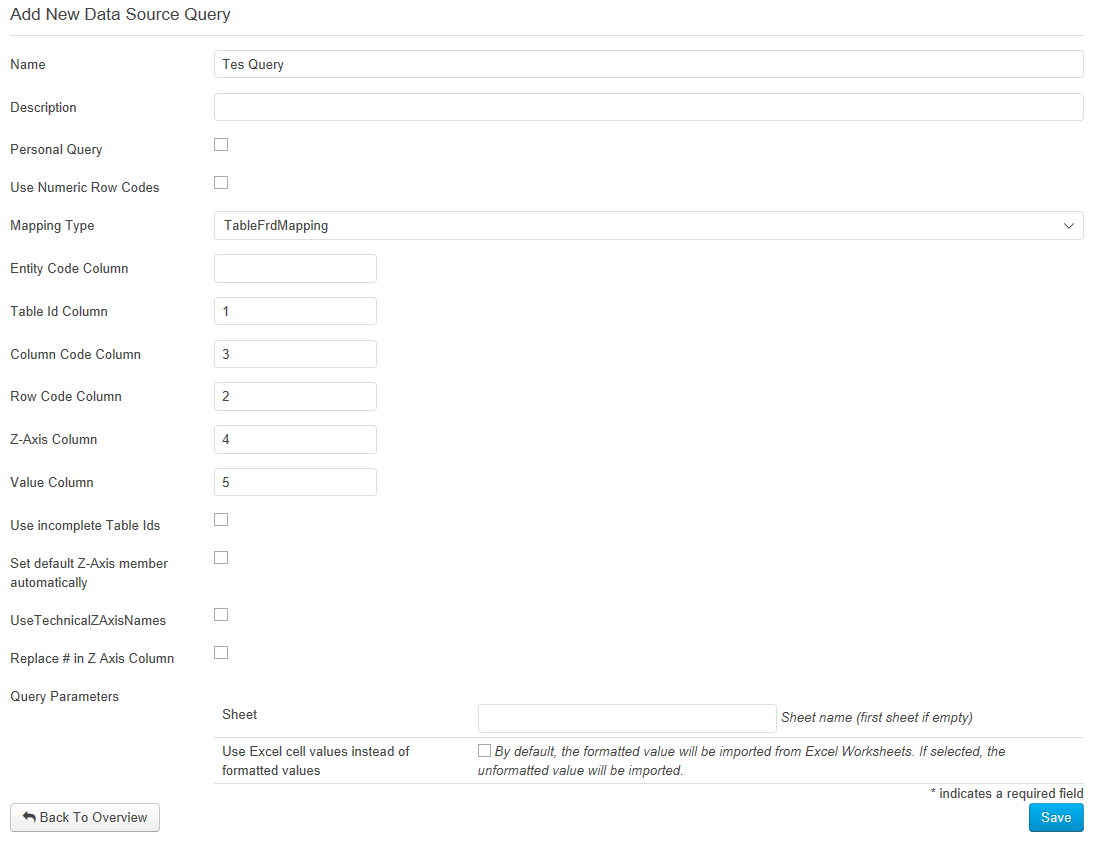
Neben dem Namen und einer Beschreibung muss ausgewählt werden, ob es sich um eine persönliche Abfrage handelt oder nicht.
Persönliche Abfragen sind nur für den Benutzer sichtbar, der sie angelegt hat.
Es gibt drei Mapping-Typen die pro Abfrage definiert werden können. Ein Mapping Typ legt fest, wie die Daten aus der Datenquelle auf die XBRL Taxonomie zugeordnet werden können.
- TableFrdMapping: Das „Form-Ready-Data" Mapping ermöglicht die Zuordnung von Daten mittels Tabellen-ID, Zeile, Spalte und Z-Achse auf Taxonomien mit Tabellen.
- TableBlobMapping: Die sog. Blob Abfragen können für Taxonomien mit Tabellen verwendet werden. Dabei wird die Tabelle „als Ganzes" von der Abfrage importiert und in XBRL übertragen. Die Zeilen und Spalten müssen dabei exakt mit denen der Taxonomie übereinstimmen.
- ConceptMapping: Das ConceptMapping erlaubt die Zuordnung von Abfrageergebnissen mittel XBRL Conceptnamen, also den Namen der Elemente und Positionen in den Taxonomien. Dieser Ansatz kann insbesondere für Taxonomien ohne Tabellen verwendet werden.
Blob-Abfragen erlauben die direkte Zuordnung einer XBRL-Tabelle aus einer Taxonomie auf die Datenquelle. Dabei ist eine Voraussetzung, dass die Datenquelle die Tabelle in einem Format anliefert, das genau dem Format der Ziel-XBRL-Tabelle entspricht. Diese muss dann auch in dem Eingabefeld „Blob-Tabellen-Id" eingegeben werden.
Blob-Abfragen sind insbesondere für offene Tabellen sinnvoll, also z.B. im Bereich Solvency II die Asset Tabellen, S.06. Für FINREP/COREP Meldungen sind dies z.B. F 40.01 oder C 29.00.
Mit den folgenden Funktionen lassen sich die Ergebnisse der Abfragen vor der Zuordnung auf die XBRL-Tabelle bearbeiten. - Transponierte Blob-Tabelle: wenn die Einstellung gesetzt ist, werden Zeilen und Spalten der Tabelle vertauscht.
- Blob-Spaltenauswahl: hier können mittels Angabe des Indexes Spalten aus der Ergebnistabelle ausgewählt und umsortiert werden. Beispiel: Die Eingabe von 0,2,1,3,5 vertauscht in einer Tabelle mit 6 Spalten die Spalte 2 und 3 und „entfernt" die fünfte Spalte, weil der Index 4 fehlt. Wenn das Eingabefeld nicht befüllt wird, wird die Ergebnistabelle der Abfrage unverändert zugeordnet.
- Blob-Zeilenauswahl: diese funktioniert für die Zeilen analog zu den Spalten.
Die Abfragen ermöglichen eine Zuordnung der Daten auf eine Tabellenstruktur durch Taxonomie-Koordinaten, wie im Beispiel illustriert.
Tabelle | Zeile | Spalte | Z-Achse / Seite | Wert |
|---|
C_01.01 | R010 | C010 |
| 1000000 | C_01.01 | R015 | C010 | |
| 500000 | C_07.00.a | R010 | C010 | 001 | 100000 | C_07.00.a | R010 | C010 | 002 | 50000 |
Damit die Zuordnung auf die Tabellen erfolgen kann, muss für die Abfrage definiert werden, wo in der Abfrageergebnisstabelle die entsprechenden Informationen zu finden sind, also mindestens die Tabellen-ID, Zeile, Spalte, Z-Achse und der Wert. Die Ergebnistabelle der Abfrage darf also beliebig viele andere Informationen bzw. Spalten enthalten.
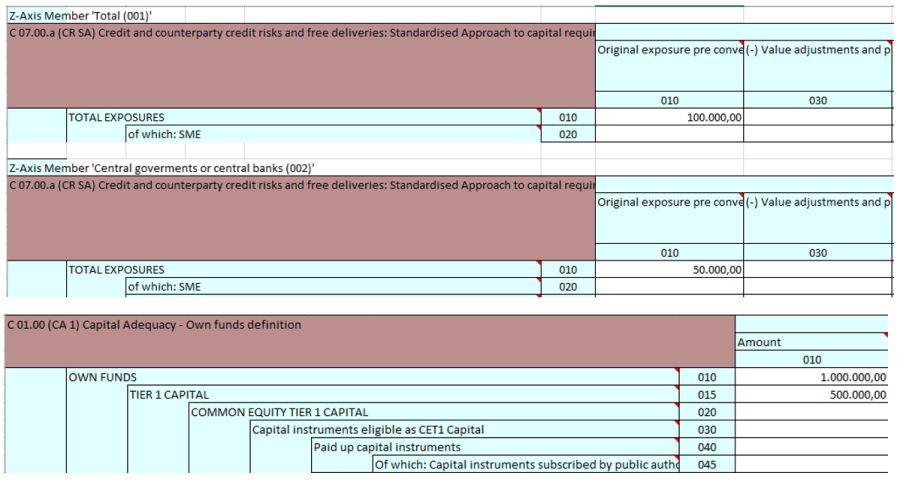
In der Abbildung sieht man die Einstellung für das gezeigte Beispiel.
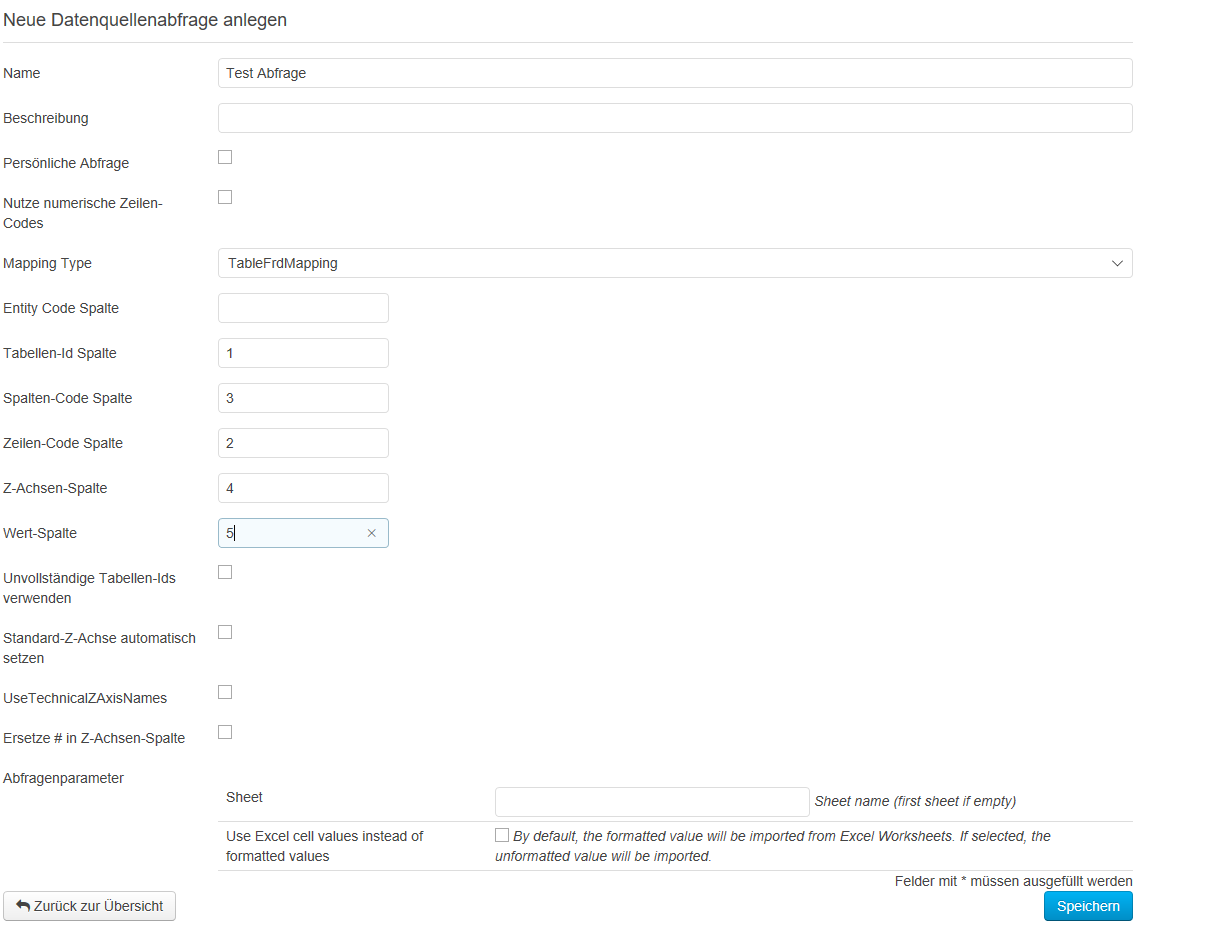
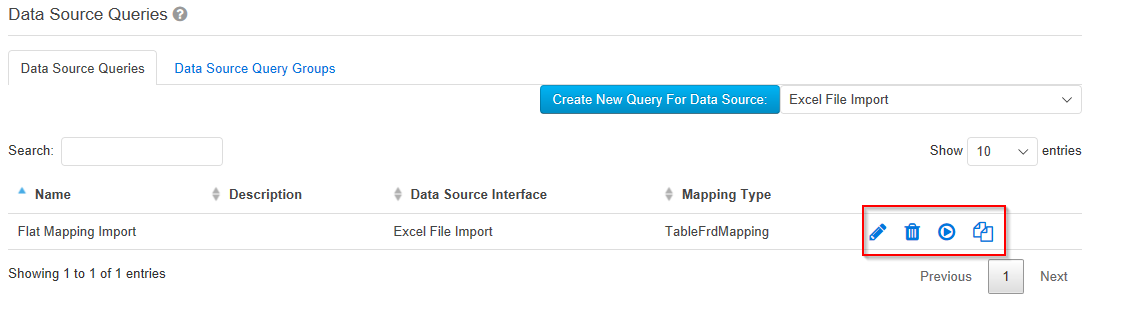
Sobald Sie alle Daten zu der neuen Abfrage eingetragen haben, klicken Sie unten auf „Speichern". Klicken Sie auf das „Stift"-Symbol, um die Änderungen an der angelegten Abfrage vorzunehmen. Die Abfragen löschen Sie, indem Sie auf das Symbol „Papierkorb" klicken. Durch einen Klick auf den „Ausführen" Button können Datenquellenabfragen zu Testzwecken ausgeführt werden. Um die Daten tatsächlich zu importieren, müssen Sie unter "Meldungen → Meldung erfassen" die im Bereich "Meldung erfassen" die Option "DataSourceQueries" auswählen.
Nachdem Sie auf „Ausführen" geklickt haben, muss in der geöffneten Ansicht nun eine Excel-Datei als Parameter ausgewählt werden. Klicken Sie anschließend auf den Button „Ausführen". Die Ergebnisse der Abfrage werden in zwei Tabellen dargestellt. Sollte durch die Einstellungen der Abfrage Veränderungen an den Daten vorgenommen werden, so werden sowohl das Ursprungsabfrageergebnis angezeigt als auch die verarbeiteten Daten.
Die erstellten Abfragen können beim Erfassen von Meldungen genutzt werden.
|