This document describes how to use the AMANA XBRL Engine to utilize XBRL instances and taxonomies.
Used Technologies
AMANA.XBRL.Engine is a class library project based on .NET 4.7.2 which can be easily embedded into any .NET 4.7.2+ project.
Usually, referenced assemblies are available automatically. However, the following components are used by the AMANA.XBRL.Engine:
- .NET 4.7.2 Framework
- Lightweight XPath2 for .NET Library available at: [[http://xpath2.codeplex.com/]]
- DotNetZip Library from the [[http://dotnetzip.codeplex.com/]]
- EPPlus Excel Spreadsheets [[http://epplus.codeplex.com/]]
- NCalc [[https://ncalc.codeplex.com/]]
Generally, all the recent versions of Windows are supported. For more information, refer to the .NET 4.7.2 System Requirements at:
System Requirements for version 4.7.2
Getting started
License File
The AMANA XBRL Engine requires a license file. The Engine will look for the license file at the following locations:
- At the processor’s default XBRL settings folder “%APPDATA%\Roaming\AMANAconsulting”.
- At the processor’s XBRL cache folder, which can be defined in the XbrlSetting’s XbrlFileCachePath property. The default value for this property is “%APPDATA%\AMANAconsulting\XBRLCache”.
- At the location, where the engine’s .dll files are stored.
XBRL Settings File
Certain functionalities of the AMANA.XBRL.Engine library can be controlled from the Settings file (named SmartXBRLSettings.xml) which resides in the AMANAConsulting directory under following path:
%APPDATA%\AMANAConsulting
A typical SmartXBRLSettings.xml file might look like this:
<?xml version="1.0"?> <XBRLSettings xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <ThrowXBRLExceptionForUnitTesting>false</ThrowXBRLExceptionForUnitTesting> <MaxValidationExceptionLimit>1000</MaxValidationExceptionLimit> <UseProxy>NoProxy</UseProxy> <ProxyPort>0</ProxyPort> <ProxyUseAuthentication>false</ProxyUseAuthentication> <XBRLFileCachePath>C:\Users\username\AppData\Roaming\AMANAconsulting\XBRLCache</XBRLFileCachePath> <ForceOfflineMode>true</ForceOfflineMode> <FillOffllineCache>true</FillOffllineCache> <ReDownloadAndOverrideCachedFiles>false</ReDownloadAndOverrideCachedFiles> <TaxonomyPackageCacheType>None</TaxonomyPackageCacheType> <DisableAsyncTaxonomyLoading>false</DisableAsyncTaxonomyLoading> <DisableBinaryCache>false</DisableBinaryCache> </XBRLSettings>
There are few settings which might alter the behavior of the Engine:
- ThrowXBRLExceptionForUnitTesting: Once set to true, forces the Engine to throw a XbrlException if one occurs.
- MaxValidationExceptionLimit: Specified in numbers defining the Validation exception limit. Once limit is reached, the Engine throws a so-called XbrlExceptionLimitReachedException exception.
- UseProxy: Once set, forces the Engine to use a Proxy Server in order to access the remote location where the taxonomy is situated. If enabled, the following Properties must be specified:
- ProxyAddress: Must be a valid string.
- ProxyPort: Must be a valid integer.
- ProxyUser: Must be a valid string.
- ProxyPasswordEncrypted: Must be a valid string.
- ProxyUseAuthentication: Must be a valid bool.
- XBRLFileCachePath: Specifies a path to local folder where the taxonomies are stored.
- ForceOfflineMode: Once enabled, forces the Engine to use the local cache where the taxonomies are located. If the taxonomies are not found, the engine will download them from the internet. The local cache path is specified by the XBRLFileCachePath setting.
- FillOffllineCache: Once set to true, enables the Engine to access remote location where a taxonomy is hosted and download it. The folder path where the taxonomy will be stored, is specified by the XBRLFileCachePath setting.
- ReDownloadAndOverrideCachedFiles: When enabled, the cached files will always be replaced with new ones loaded from the internet.
- TaxonomyPackageCacheType: Select in which form the taxonomy packages will be stored. You can choose between None, Extracted and Zip.
- DisableAsyncTaxonomyLoading: Once enabled, the files of a taxonomy are read asynchronously instead of one after another.
- DisableBinaryCache: When set to false, the faster binary cache is used. If a file is not found, the Engine will look for it in the cache folder.
The settings can be stored as an XML file using it’s static Save method:
var settings = new XbrlSettings(); XbrlSettings.Save(settings, @"C:\path\settings.xml");
The XbrlSettings class also provides a method for loading such an XML file:
var settings = XbrlSettings.Load(@"C:\path\settings.xml");
XBRL Offline Cache
The XBRL Offline Cache is a built-in functionality of the AMANA.XBRL.Engine allowing the Taxonomy Discovery Process to process local versions of taxonomies. This feature speeds up the entire discovery process in comparison with the online mode. Prior to running taxonomy discovery against local data (either processing taxonomy or instance), the taxonomy has to be locally cached (in other words, saved on the local file system). The path to the local cache folder is specified by the XBRLFileCachePath property. In order to activate the feature, the following steps should be undertaken:
- Set FillOffllineCache property to true. This enables the Engine to save taxonomies on the local file system as soon as they are loaded from the internet. By activating this property, all files downloaded from a remote source will be stored in the cache folder.
- Set the ForceOfflineMode. This option forces the AMANA.XBRL.Engine to access taxonomies from local file system.
The following example shows how a remotely referenced file will then be stored in the local cache folder.
Remote reference:
http://www.eba.europa.eu/eu/fr/xbrl/crr/fws/corep/its-2014-05/2015-02-16/mod/corep_ind.xsd
Local folder path:
C:\Users\user.name\AppData\Roaming\AMANAconsulting\XBRLCache\www.eba.europa.eu\eu\fr\xbrl\crr\fws\corep\its-2013-02\2014-07-31\mod\corep_ind.xsd
Loading XBRL Documents
Processor
The Processor class is responsible for loading XBRL documents, like XBRL taxonomies or XBRL instance files. The default constructor will try to read the XBRL settings file from the default settings location “%APPDATA%/Roaming/AMANAconsulting/SmartXBRLSettings.xml”:
var processor = new Processor();
The path to the XBRL settings file can also be passed as a string:
var processor = new Processor(@"C:\path\XBRLSettings.xml");
You can also create an XbrlSettings object, which keeps the settings and passes it to the constructor. The settings from this settings object will be used instead of the deafult settings. You can access the processor’s settings using its Settings property.
var xbrlSettings = new XbrlSettings(); var processor = new Processor(xbrlSettings);
How to open/read a XBRL Taxonomy
AMANA.XBRL.Engine allows loading taxonomies from both Url (remote location) and local file system. A taxonomy can be loaded using the processor’s ReadXbrlTaxonomy method. You can pass the path to a locally stored taxonomy, which will be read by the processor:
var taxonomy = processor.ReadXbrlTaxonomy(
@"C:\EIOPA\eiopa.europa.eu\eu\xbrl\s2md\fws\solvency\solvency2\2015-10-21\mod\ars.xsd");
In this case, the entry point of the taxonomy will be the file path! This can lead to problems, e.g. when generating an instance document. It is recommended to use the entry point of the desired taxonomy and e.g. pass it as an URL. This can be done by passing the entry point to the processor, which will then download the taxonomy:
var taxonomy = processor.ReadXbrlTaxonomy(
"http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2015-10-21/mod/ars.xsd");
The URL can also be passed as an URI object.
var uri = new Uri(
"http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2015-10-21/mod/ars.xsd");
var taxonomy = processor.ReadXbrlTaxonomy(uri);
When loading a XBRL taxonomy via an URL, the processor can be configured to first look for the XBRL schema files in the local cache. If the schema files are not found, it will try to load the files via the internet. By default, all downloaded files are stored in the XBRL cache folder. The cache folder, proxy settings and other settings can be configured in the Processor’s settings file.
Taxonomy Validation
A loaded taxonomy can also be validated to check if it fulfills the XBRL specification by calling it’s Validate method, which conducts explicit XML schema validation:
var processor = new Processor();
var taxonomy = processor.ReadXbrlTaxonomy(
"http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2015-10-21/mod/ars.xsd");
taxonomy.Validate();
var validationResults = taxonomy.TaxonomyResultSet.GetItems().ToList();
The Validate(GenericLinkbaseContainer container = null) function has an optional parameter of type GenericLinkbaseContainer, which contains all generic links. If it exists, all the contained links are validated as well. After calling the Validate method, the TaxonomyResultSet property of the XbrlTaxonomy will be filled. Each item within this result set is a single validation error. To get all items, call the TaxonomyResultSet.GetItems() method, which will return an IEnumerable of IValidationResult objects. The most important properties of IValidationResult are:
- IsValid: Specifies whether the taxonomy is valid or not.
- Message: A validation error message.
- Message: Specifies validation message.
- Severity: Specifies message severity. Following Enum values can only be assigned with the property:
Error
Warning
Information
- Type: Specifies the validation type which is restricted to one of the following (Enum):
- TaxonomySpec21
- TaxonomyXml
- TaxonomySec
- InstanceXml
- InstanceSpec21
- InstanceSec
- InstanceEBilanz
- TaxonomyTableLinkbaseSpec
- InstanceTableLinkbaseSpec
- TaxonomyDimensionSpec
- InstanceDimensionSpec
- InstanceFormulaSpec
- TaxonomyFormulaSpec
- TaxonomyExtensibleEnumerations
- InstanceExtensibleEnumerations
- FilingRules
- InlineXbrl
- InlineXbrlSchema
- InlineXhtmlSchema
- ReportGeneration
- ReportMapping
- Other
- RuleId: The ID of the rule specified by the taxonomy.
- Rule: The rule definition itself.
Taxonomy Caching Processor
The TaxonomyCachingProcessor provides faster access to taxonomies that are referenced by a remote Uri by keeping them cached in the memory after they are opened for the first time. It is highly recommended to use this feature for servers or in constantly running applications. By default, cached taxonomies removed from the memory after 2 days or when the memory usage of the system reaches 95%. The TaxonomyCachingProcessor provides a ReadXbrltaxonomy just like the XbrlProcessor. The following example shows how to open a taxonomy with the TaxonomyCachingProcessor . When the same taxonomy is read at a later point, it will be loaded directly from the cache in the memory.
TaxonomyCachingProcessor taxCacheProcessor = new TaxonomyCachingProcessor();
Uri uri = new Uri("http://www.eba.europa.eu/eu/fr/xbrl/crr/fws/ae/cir-680-2014/2018-03-31/mod/ae_con.xsd");
XbrlTaxonomy tax = taxCacheProcessor.ReadXbrlTaxonomy(uri);
How to open a XBRL Instance Document
The XbrlDocument class provides the XbrlInstances property, which contains the instances data. The most important properties are:
List<FactBase> Facts: Facts, i.e. reported data, of the instance document.
Dictionary<XmlQualifiedName, List<FactBase>>BaseFactsByElement: Facts by the XML qualified name of the corresponding concept/metric.
List<Context> Contexts: All contexts defined in the instance document.
List<Units> Units: All units defined in the instance document.
List<XbrlTaxonomy> Schemas: The XBRL taxonomies/schemas, which are used by the instance document.
To load an XBRL instance file, use the Processor’s LoadXbrlDocument method. For example this will load a locally stored file:
var xbrlDocument = processor.LoadXbrlDocument(@"C:\path\xbrlInstance.xml");
It is also possible to pass a Stream or an XmlReader to this method:
using (var stream = new FileStream(@"C:\path\xbrlInstance.xml", FileMode.Open))
{
var xbrlDocument = processor.LoadXbrlDocument(stream);
}
Validation
XBRL Instance Validation
When loading an instance document, the XBRL taxonomies which are referred by the instance, will also be loaded. The instance file can be validated against the XBRL schema and validation rules defined in the referenced taxonomy files by calling the method XbrlDocument.Validate(bool validateXbrlTaxonomies, bool attachResultsToFacts, GenericLinkbaseContainer container = null):
The Validate() method accepts the following parameters:
- bool validateXbrlTaxonomies: Boolean parameter specifing whether the taxonomy, which the provided instance conforms to, should be validated as well.
- bool attachResultsToFacts: If set to true, all fact related validation results will be included in the Fact.ValidationResults List.
- GenericLinkbaseContainer container: The container which stores all generic links of the XBRL taxonomy. Can usually be ignored.
There are two more overloads:
- Validate(): Skips the validation of the XbrlTaxonomy itself (equal to Validate(true, false) ).
- Validate(bool validateXbrlTaxonomies, GenericLinkbaseContainer container = null): The fact related validation results will not be included in the Fact.ValidationResults list.
The method can be called as follows:
XbrlDocument xbrlDoc = new XbrlDocument(); xbrlDoc.Load(@"c:\testInstanz.xml"); xbrlDoc.Validate(); //Skips the validation of the XbrlTaxonomy itself
The Validate() method conducts explicit XML schema validation. The results of the validation can be easily retrieved using GetItems() method of XbrlDocument.DocumentResultSet property:
IEnumerable<XbrlMessage> messages = xbrlDoc.DocumentResultSet.GetItems();
Formula Validation
The AMANA.XBRL.Engine supports formula validation per XBRL Formula Linkbase specification. The Formula validation can be simply initiated by the extension method ValidateIncludingFormula() of the XbrlDocument class:
using AMANA.XBRL.Engine.Plugin.FormulaLinkbase;
// starting formula validation
instanceDocument.ValidateIncludingFormula(
validateTaxonomies: false,
verbose: false,
attachResultsToFacts: false,
new List<string>(),
new List<string>());
var resultList = instanceDocument.DocumentResultSet.GetItems();
This method first performs XBRL instance validation with optional taxonomy validation. This is because before formula invocation we should have a valid instance document. If XBRL instance validation fails, the formula validation will not run. The result of the formula validation is included in the DocumentResultSet property of the XbrlDocument class.
The behaviour of formula validation can be controlled using the following function parameters:
- validateTaxonomies: The parameter specifies whether the taxonomy, which the provided instance conforms to, should be validated as well. The taxonomy validation is not necessary for performing formula validation.
- verbose: Once enabled, forces the validator to display/log all messages generated during the formula validation. Can be used for detailed analysis.
- attachResultsToFacts: if enabled, forces formula processor attach errors to related facts for future references. It allows tracking errors by each fact for user UI for example.
- InclusionIds: The list of string specifying Validation Formula IDs which should be performed in formula validation.
- ExclusionIds: On the contrary, the ExclusionIds specifies the list of Validation Formula IDs which should be skipped during the formula validation.
- EnableTPL: Enables using .NET Task Parallel Library to speed up Formula processing performance. This option is enabled by default.
Filing Rule Validation
Many authorities define filing rules, a set of additional rules which are not defined in the XBRL taxonomy itself. Hence those rules are manually programmed in the Engine DLL files. If the filing rules are updated, an update of the engine is also needed. To run file rule validaitons for an XBRL instance document, an FilingRulesValidator object must be created. In the following codeblock, a method ValidateInstance is written which demonstrate how to use the FilingRulesValidator
private void ValidateInstance(XbrlInstance instance)
{
var validator = new FilingRulesValidator();
validator.LoadRules(Regulator.EBA4_3, false);
List<FilingRuleValidationMessage> validationResults = validator.Validate(instance);
foreach (var result in validationResults)
Console.WriteLine($"{result.RuleId}: {result.Message}");
}
After creating the FilingRulesValidator, the rules which should be validated are loaded via its LoadRules method. The rules are validated using the method Validate. Validation results are returned as a List of FilingRuleValidationMessageObjects. The following list shows the methods of the class FilingRulesValidator:
| Method | Description |
|---|---|
| LoadRules(Regulator, bool) | Loads the rules which should be validated. The first parameter defines the regulator and version of a specific filing rule set. Regulator is a enum defined in the Engine. The second parameter defines if the rule for validating the file name should also be loaded. |
| LoadRules(Regulator, List<string>, bool, bool) | Loads the rules which should be validated. The first parameter defines the regulator and version of a specific filing rule set. As second parameter, a list of validation rule names can be passed. If the third parameter is set to true, only those rule, which name contains any string in the list of validation rules will be validated. If set to false, rules whose name contains any of the passed strings will be excluded. The last boolean parameter defines if the rule for validating the file name should also be loaded. |
| GetRuleNames(Regulator, bool) | Gets the name of all rules for a specific rule set. The first paramter defines the regulator and version of a specific rule set. The second parameter defines if the rule for validating the file name should also be loaded. |
| Validate(XbrlInstance) | Validates the instance documents using the rules which were previously loaded using the LoadRules method. |
The FilingRuleValidationMessage class has the following attributes:
| Name | Description |
|---|---|
| Name | The name of the corresponding filing rule. |
| IsValid | Indicates if the instance fulfills the filing rule. |
| IsException | Indicates if an Exception occured during the validation of the filing rule. |
| Message | The message which indicates the reason why the instance does not fulfill the filing rule. |
| RuleId | The ID of the corresponding filing rule. |
| Rule | The name of the corresponding filing rule. |
| Type | Returns always the enumaration value ValidationTypes.XbrlValidaitonType.FilingRules. |
| Severity | Returns the severity of the error. The severity is a value of the enum ValidationTypes.Severity, which can have one of the following values: Error, Warning, Information. |
Generating XBRL Instance
AMANA.XBRL.Engine facilitates seamless XBRL Instance generation process. The instance generation process can easily be organized into 4 logical steps:
- Context synthesis
- Filing Indicators generation
- Unit generation
- Facts generation
First, an object of type XbrlInstance must be derived from the XbrlDocument object:
_processor = new Processor(); string taxonomyFile = @"C:\taxonomy.xsd"; XbrlTaxonomy taxonomy = _processor.ReadXbrlTaxonomy(taxonomyFile ); var taxonomies = new List<XbrlTaxonomy>(); taxonomies.Add(taxonomy); XbrlDocument doc = XbrlDocument.Create(_processor, taxonomies); XbrlInstance instance = doc.Instance;
Contexts
XBRL Context is represented by the Context class. A context element contains information about the Entity, the period and dimensional information of reported facts. Each context within an instance has a unique ID.
Entity Information
There are two relevant entity information, which are reported in every context node:
- Identifier: An ID to identify an entity, e.g. an LEI code or SEC's Central Index Key (CIK).
- Identifier scheme: An URI which represents the type of ID used, e.g. http://standards.iso.org/iso/17442 for LEI codes or http://www.sec.gov/CIK for SEC's CIK.
Period Information
There are three different types of periods which can be expressed:
- Instant: A point in time. Can be used to express a value for a metric in a specific point in time.
- Duration: A period with a specified beginning and ending. Can be used to express the change of a value during a specified period.
- Forever: Can be used to express that a value is always valid.
Dimensional Information
The context also contains dimensional information from explicit and typed dimensions. Those are either grouped within a scenario or a segment. If an element in the taxonomy is the primary item of a hypercube, the context must contain dimension information according to the hypercube. There are two types of dimensions:
- Explicit dimension: An explicit dimension defines a set of valid values which can be used for this dimension, e.g. a dimension "Country" may list all countries which can be used. Those values are also called "dimension members".
- Typed dimension: For typed dimensions any value can be used, e.g. a table in which a row for each instrument should be reported can include a dimension "Instrument codes".
A single context can contain both, explicit and typed dimensions.
Example 1 - Multiple Explicit Dimensions
Explicit dimensions will be explained using the example below, which displays a role from the definition linkbase of the full IFRS entry point from 2019.
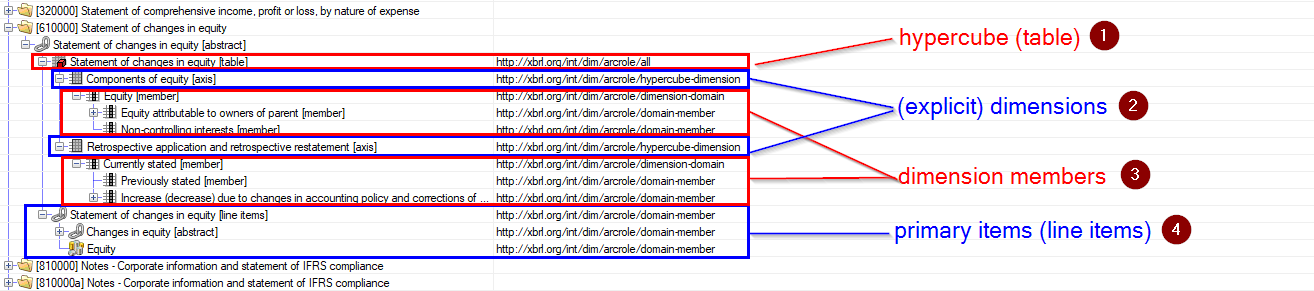
The role has the hypercube "Statement of changes in equity" (1). This cube is added to the role using an arc with the role "http://xbrl.org/int/dim/arcrole/all". This arcrole states that if a value for any primery item (4) is reported, you have to report also values for each dimension which is part of the hypercube in the value's context. The hypercube has two explicit dimensions (2): "Components of equity" and "Retrospective application and retrospective restatement". So for both dimensions one of it's dimension members (3) must be reported. E.g. for the dimension "Components of equity" the member "Non-controlling interests" and for the dimension "Retrospective application and retrospective restatement" the member "Previously stated" could be reported.
It is possible to report the line item "Equity" multiple times for the same period, but with different dimension member combinations.
Example 2 - Typed Dimensions
Typed dimensions will be explained using the example below, which displays a role from the Solvency II ARS taxonomy from version 2.4:
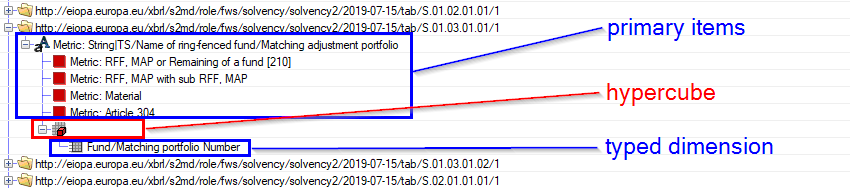
Again a list of primary items is linked with a hypercube. This Hypercube has only one typed dimension "Fund/Matching portfolio number". So if a value for "Metric: Material" should be added, its context must include the dimension "Fund/Matching portfolio Number" and a value for this dimension. Because this dimension is a typed dimensions, there are no predefined values (i.e. dimension members).
Adding Contexts
For adding Contexts, it is recommended to use the method AddInstantContext or AddDurationContet defined in the XbrlInstance class. Those methods create a context with either a instant period or a duration period and add it directly to the instance. The following code creates an instance document for EIOPA's ARS taxonomy and adds a context and a fact for reporting the company name:
// Load the taxonomy
Processor processor = new Processor();
XbrlTaxonomy taxonomy = processor.ReadXbrlTaxonomy("http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2019-07-15/mod/ars.xsd");
// Create a new document (report) for the taxonomy
XbrlDocument xbrlDocument = processor.CreateXbrlDocument(taxonomy);
// Get the element with the name si1376, which is the element used for reporting the name of the company
Element undertakingNameElement = taxonomy.GetElementByLocalName("si1376");
Context context;
// Check the element's period type to determine if a context with an instant period or a context with a duration period must be created
if (undertakingNameElement.PeriodType == Element.ElementPeriodType.Instant)
{
// Create a new context with a instant context
context = xbrlDocument.Instance.AddInstantContext(
// ID of the new context, which must be unique for the current document
"instantContext",
// instant date of the new context
new DateTime(2020, 12, 31),
// identification code of the reporting entity
"LEI/SAMPLELEICODE",
// type of the identification code
"http://standards.iso.org/iso/17442");
}
else
{
// Create a new context with a duration context
context = xbrlDocument.Instance.AddDurationContext(
// ID of the new context, which must be unique for the current document
"instantContext",
// start date of the new context
new DateTime(2020, 1, 1),
// end date of the new context
new DateTime(2020, 12, 31),
// identification code of the reporting entity
"LEI/SAMPLELEICODE",
// type of the identification code
"http://standards.iso.org/iso/17442");
}
// Add a fact for the element using the previously generated context
xbrlDocument.Instance.AddTextualFact(context, undertakingNameElement, "AMANA consulting GmbH");
The example below demonstrates how to create a context with explicit dimensions based on the example "Example 1 - Multiple Explicit Dimensions" in the chapter "Dimensional Information" above:
// Load the taxonomy
var processor = new Processor();
var taxonomy = processor.ReadXbrlTaxonomy("http://xbrl.ifrs.org/taxonomy/2019-03-27/full_ifrs_entry_point_2019-03-27.xsd");
// Create a new document (report) for the taxonomy
var document = XbrlDocument.Create(processor, new List<XbrlTaxonomy> { taxonomy });
// Get the dimension element & the member element for the axes
var firstAxis = taxonomy.GetElementByLocalName("ComponentsOfEquityAxis");
var memberForFirstAxis = taxonomy.GetElementByLocalName("NoncontrollingInterestsMember");
var secondAxis = taxonomy.GetElementByLocalName("RetrospectiveApplicationAndRetrospectiveRestatementAxis");
var memberForSecondAxis = taxonomy.GetElementByLocalName("PreviouslyStatedMember");
// Create a dictionary for the dimensions and members
// Each entry in the dictionary is a combination of a dimension and it's member
// The first element is the name of the dimension
// The second element is the name of the member
// The order of the elements in this dictionary is not relevant
var explicitDimensions = new Dictionary<XmlQualifiedName, XmlQualifiedName>();
explicitDimensions.Add(firstAxis.QualifiedName, memberForFirstAxis.QualifiedName);
explicitDimensions.Add(secondAxis.QualifiedName, memberForSecondAxis.QualifiedName);
Context context = document.Instance.AddInstantContext(
// ID of the new context, which must be unique for the current document
"instantContextId",
// instant date of the new context
new DateTime(2019, 12, 31),
// identification code of the reporting entity
"AMANA consulting GmbH",
// type of the identification code
"http://www.sec.gov/CIK",
// explicit dimensions
explicitDimensions,
// typed dimensions
null,
// dimension container, usually always scenario must be used
DimensionContainer.Scenario
);
The example below demonstrates how to create a context with explicit dimensions based on the example "Example 2 - Typed Dimensions" in the chapter "Dimensional Information" above:
// Load the taxonomy
var processor = new Processor();
XbrlTaxonomy taxonomy = processor.ReadXbrlTaxonomy("http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2019-07-15/mod/ars.xsd");
// Create an XBRL instance document based on the loaded taxonomy
XbrlDocument document = processor.CreateXbrlDocument(taxonomy);
// Get the element with the name si1376, which is the element used for reporting the name of the fund/portfolio
Element fundPortfolioNameElement = taxonomy.GetElementByLocalName("si1376");
// Get the dimension element
var typedAxis = taxonomy.GetElementByLocalName("FN");
// Create a dictionary for the dimensions and values
// Each entry in the dictionary is a combination of a dimension and it's value
// The first element is the name of the dimension
// The second element is the value for this dimension
// The order of the elements in this dictionary is not relevant
var typedDimensions = new Dictionary<XmlQualifiedName, string>();
typedDimensions.Add(typedAxis.QualifiedName, "typedValue");
Context context = document.Instance.AddInstantContext(
// ID of the new context, which must be unique for the current document
"instantContextId",
// instant date of the new context
new DateTime(2019, 12, 31),
// identification code of the reporting entity
"LEI/SAMPLELEICODE",
// type of the identification code
"http://standards.iso.org/iso/17442",
// explicit dimensions
null,
// typed dimensions
typedDimensions,
// dimension container, usually always scenario must be used
DimensionContainer.Scenario
);
// Add a fact for the element using the previously generated context
document.Instance.AddTextualFact(context, fundPortfolioNameElement, "fact value");
The following methods defined in the class XbrlInstance can be used for creating and adding a new context to an instance:
| Method | Description |
|---|---|
| AddInstantContext(string, DateTime, string, string) | Adds an context with an instant period to the XBRL instance. The parameters are:
|
| AddInstantContext(string, DateTime, string, string, Dictionary<XmlQualifiedName, XmlQualifiedName>, Dictionary<XmlQualifiedName, string>, DimensionContainer) | Adds an context with an instant period to the XBRL instance. The parameters are:
|
| AddInstantContext(string, DateTime, string, string, Dictionary<XmlQualifiedName, XmlQualifiedName>, Dictionary<XmlQualifiedName, string>, DimensionContainer, bool) | Adds an context with an instant period to the XBRL instance. The parameters are:
|
| AddDurationContext(string, DateTime, DateTime, string, string) | Adds an context with an instant period to the XBRL instance. The parameters are:
|
| AddDurationContext(string, Datetime, DateTime, sting, string, Dictionary<XmlQualifiedName, XmlQualifiedName>, Dictionary<XmlQualifiedName, string>, DimensionContainer) | Adds an context with an instant period to the XBRL instance. The parameters are:
|
| AddDurationContext(string, DateTime, DateTime, string, string, Dictionary<XmlQualifiedName, XmlQualifiedName>, Dictionary<XmlQualifiedName, string>, DimensionContainer, bool) | Adds an context with an instant period to the XBRL instance. The parameters are:
|
Units
XBRL units define XBRL fact measurements. E.g. a specific currency or pure, which is used for percentages. Units consist of numerators and optionally denominators. In most cases, only a numerator is needed to express a specific unit. E.g. If the unit of a fact is Euros, the unit consists of the numerator Euro. No denominator is needed in this case.
Denominators are only needed to express divisions. E.g. to express the earnings per share in euro, a unit is nedded with Euro as numerator and shares as denominator.
A numerator and a denominator is a XmlQualifiedName. The constant XbrlBaseConstants.Iso4217, defined in AMANA.XBRL.Engine as "http://www.xbrl.org/2003/iso4217", can be used as namespace for adding monetary units. To create a new unit and add it to an existing instance, use the method AddUnit defined in the class XbrlInstance. The following code adds the unit "EURO" to an existing instance:
XmlQualifiedName unitCode = new XmlQualifiedName("EUR", XbrlBaseConstants.Iso4217);
var numerators = new List<XmlQualifiedName>();
var denominators = new List<XmlQualifiedName>();
numerators.Add(unitCode);
Unit unit = instance.AddUnit("EURO", numerators, denominators);
This code will add the following XML node to the instance document:
<xbrli:unit id="EURO"> <xbrli:measure>iso4217:EUR</xbrli:measure> </xbrli:unit>
The following overloads for this method exists:
| Method | Description |
|---|---|
| AddUnit(string, XmlQualifiedName) | Adds an unit to the instance. The parameters are:
|
| AddUnit(string, List<XmlQualifiedName>) | Adds an unit to the instance. The parameters are:
|
| AddUnit(string, List<XmlQualifiedName>, List<XmlQualifiedName>) | Adds an unit to the instance. The parameters are:
|
Facts
A XBRL fact is represented by the Fact class. Most facts are either numeric or textual, depending on the value which can be reported for the fact's metric. The metric/element from the XBRL taxonomy has a data type which defines what kind of values can be reported for this metric. Examples for types of numeric elements are:
- monetary
- percent
- pure
- decimal
- integer
Examples for types of textual elements:
- QName
- enumeration
- date
- boolean
- string
The class XbrlInstance features two methods to add mentioned facts: AddMonetaryFact for adding numeric facts and AddTextualFact for adding textual facts.
| Method | Description |
|---|---|
| AddNumericFact(Context factContext, Unit factUnit, Element factElement, decimal value, int? decimals, int? precision = null, bool infiniteDecimals = false, string elementId = "") | Adds a numeric fact to the instance document. The parameters are:
|
| AddNumericFact(Context factContext, Unit factUnit, Element factElement, decimal value, string elementId = "") | Adds a numeric fact to the instance document with the decimal attribute set to "INF" which states that the exact value is reported. The parameters are:
|
| AddTextualFact(Context factContext, Element factElement, string value, string elementId ="") | Adds a fact to the instance document and sets the fact's value as value of the XmlNode.Value property. The value will be parsed (e.g. "&" becomes "&" and "<" becomes "<"). The parameters are:
|
| AddNilFact(Context factContext, Element factElement, bool nil, string elementId = "") | Adds a new fact with the attribute xsi:nil to the XBRL instance document. If necessary, a nil fact can be added to explicitly state that no value is reported by setting the value of the xsi:nil attribute to true. If no value can be reported for a certain metric (element) from the XBRL taxonomy, usually no fact at all is reported. Regulators usually define if and in which cases the usage of xsi:nil="true" is allowed. Usually it is not necessary to add the xsi:nil fact attribute if it's value is false. The parameters are:
|
| AddNilFact(Context factContext, Unit factUnit, Element factElement, bool nil, string elementId = "") | Adds a new fact with the attribute xsi:nil to the XBRL instance document. If necessary, a nil fact can be added to explicitly state that no value is reported by setting the value of the xsi:nil attribute to true. If no value can be reported for a certain metric (element) from the XBRL taxonomy, usually no fact at all is reported. Regulators usually define if and in which cases the usage of xsi:nil="true" is allowed. Usually it is not necessary to add the xsi:nil fact attribute if it's value is false. The parameters are:
|
The following example illustrates how to create and save a new XBRL instance for Solvency II ARS Version 2.4 and add a new textual fact for reporting the name of the reporting entity:
// Load the taxonomy
Processor processor = new Processor();
XbrlTaxonomy taxonomy = processor.ReadXbrlTaxonomy("http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2019-07-15/mod/ars.xsd");
// Create a new instance document for the taxonomy
XbrlDocument xbrlDocument = processor.CreateXbrlDocument(taxonomy);
// Get the element with the name si1376, which is the element used for reporting the name of the company
Element undertakingNameElement = taxonomy.GetElementByLocalName("si1376");
// Create a new instant context for the element.
Context context = xbrlDocument.Instance.AddInstantContext(
"instantContext",
new DateTime(2020, 12, 31),
"LEI/SAMPLELEICODE",
"http://standards.iso.org/iso/17442");
// Add a fact for the element using the previously generated context.
xbrlDocument.Instance.AddTextualFact(context, undertakingNameElement, "AMANA consulting GmbH");
// Save the XBRL instance document.
xbrlDocument.Save(@"C:\path\instance.xbrl");
Footnotes
Footnotes are additional information to reported facts. The screenshot below shows a fact within the XBRL instance document including a single footnote:
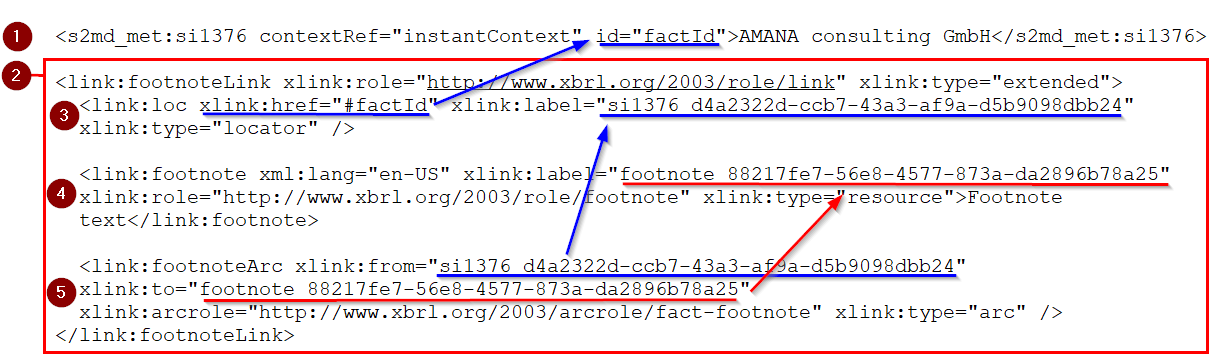
The following parts participate in this case:
- The fact itself: All facts for which a footnote should be assigned need an ID. In this case the ID is "factId".
- A footnote linkbase: All footnotes are stored within a separate block within the instance document.
- A locator: The locator represents the fact within the footnote linkbase. The locator's xlink:href attribute contains the ID of the fact which it represents. It also has a xlink:label attribute which is used by other elements to refer to this locator.
- A footnote: The footnote itself. Within the XML node is the actual text of the footnote. The footnote has also a xlink:label attribute which is used by other elements to refer to this footnote.
- A footnoteArc: The footnote arc connects a footnote with a locator. The value of the attribute xlink:from is the xlink:label of the locator, the value of the attribute xlink:to is the xlink:label of the footnote. The locator contains a reference to the reported fact, such a link between footnote and fact is created.
Locators and Footnotes can be reused:
- If a fact has multiple footnotes, only one locator is needed. Then for each footnote a footnoteArc is added to the instance document. Those footnoteArcs have all the same value for the xlink:from attribute, because they are referring to the same locator. Only the value of the xlink:to attribute differs, because they are referring to different footnotes.
- If the same footnote is used for multiple fact, e.g. all values within a column for a reported table should get the same footnote, only one footnote is needed. In this case for each fact a footnoteArc is added to the instance document. The value for the xlink:from attribute are the labels of the facts' locators, but the value of the xlink:to attribute for all those footnoteArcs is the xlink:label of the footnote.
The following code illustrates how to add a footnote to an XBRL instance document:
// Load the taxonomy.
var processor = new Processor();
XbrlTaxonomy taxonomy = processor.ReadXbrlTaxonomy("http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2019-07-15/mod/ars.xsd");
// Create an XBRL instance document based on the loaded taxonomy.
XbrlDocument document = processor.CreateXbrlDocument(taxonomy);
// Add a fact to the document.
Element undertakingNameElement = taxonomy.GetElementByLocalName("si1376");
Context context = document.Instance.AddInstantContext(
// ID of the new context, which must be unique for the current document
"instantContext",
// instant date of the new context
new DateTime(2020, 12, 31),
// identification code of the reporting entity
"LEI/SAMPLELEICODE",
// type of the identification code
"http://standards.iso.org/iso/17442");
Fact fact = document.Instance.AddTextualFact(
// The context of the reported value.
context,
// The element for which the value is reported.
undertakingNameElement,
// The value which should be reported for the element.
"AMANA consulting GmbH",
// Facts need an ID so that a footnote can be linked to it.
// The ID must start with a letter.
"factId");
// All footnotes within an instance document are stored within a separate container
// called FootnoteLink
FootnoteLink footnoteLink = document.Instance.AddFootnoteLink();
// A locator for this fact is added to the FootnoteLink.
// This locator refers to the fact which is passed to the method as parameter.
FootnoteLocator factLocator = footnoteLink.AddLocator(fact);
// When adding the actual footnote, the language of the footnote must be specified.
var footnoteLanguage = new CultureInfo("en-US");
Footnote footnote = footnoteLink.AddFootnote(footnoteLanguage, "Footnote text");
// A link between the Footnote and the fact's locator is created.
// It is possible to create multiple links using the same footnote (i.e. the same footnote is linked to different values).
// It is possible to create multiple links using the same fact locator (i.e. the same fact has multiple footnotes).
footnoteLink.AddFootnoteArc(factLocator, footnote);
Filing Indicators
Filing indicators are used to indicate what tables (data from the tables) are reported in the instance file. Filing indicators can be retrieved from a supplied taxonomy. A common practise is to employ the following statements:
Element fIndicatorsElement = taxonomy.GlobalElements["find:fIndicators"]; Element filingIndicatorElement = taxonomy.GlobalElements["find:filingIndicator"]; Tuple fIndicators = instance.AddTupleToInstance(fIndicatorsElement);
In order to make the instance file be conform with the filing rules, filing indicators must refer to a separate context element. Such can easily be done using the following code:
Context cf = instance.AddInstantContext("c-filingIndicators", DateTime.Now, "AMANA", "http://companyName.de");
The AddInstantContext(string id, DateTime instantDate, string identifier, string identifierScheme) method accepts the following parameters: string id: The unique id of the context, DateTime instantDate: The instant date of the duration period, string identifier: The identifier of the context, string identifierScheme: The identifier scheme of the context.
A Filing indicator is a special kind of fact, thus, it is appended to the instance the same way as an ordinary XBRL fact:
Fact filingInd = new Fact(InstanceDocument.XbrlInstances, filingIndicatorElement, cf); filingInd.Value = tableResolvedTableHierachy.ParentTable.FilingIndicatorLabel.InnerText; instance.AddFactToTuple(fIndicators, filingInd);
tableResolvedTableHierachy is the instance of TableResolvedTableHierachy class representing the resolved XBRL table hierarchy. Usually tableResolvedTableHierachy is pulled from role.ResolvedTableHierachies() method where role is a member of Taxonomy.GlobalResolvedRoleTypes collection. Below is the sample of how filing indicators can look like in the instance file:
<find:fIndicators> <find:filingIndicator contextRef="c0">C_26.00</find:filingIndicator> <find:filingIndicator contextRef="c0">C_27.00</find:filingIndicator> <find:filingIndicator contextRef="c0">C_28.00</find:filingIndicator> <find:filingIndicator contextRef="c0">C_29.00</find:filingIndicator> <find:filingIndicator contextRef="c0">C_30.00</find:filingIndicator> <find:filingIndicator contextRef="c0">C_31.00</find:filingIndicator> </find:fIndicators>
Handling Duplicate Facts
XBRL defines the facts X and Y as duplicates if all of the following conditions apply:
- X is not identical to Y, and
- The element local name of X is S-Equal (Structure-equal: XML nodes that are either equal in the XML value space, or whose XBRL-relevant sub-elements and attributes are s-equal.) to the element local name of Y, and
- X and Y are defined in the same namespace, and
- X is P-Equal (Parent-equal: instance items or tuples having the same parent.) to Y, and
- X is C-Equal (Context-equal: Items or sets or sequences of items having the same item type in s-equal contexts.) to Y, and
- X is U-Equal (Unit-equal: u-equal numeric items having the same units of measurement.) to Y, and
- X and Y are dimensionally equivalent (d-equal in all dimensions of each of X and Y; Two facts are d-equal for one dimension if they have the same dimension value for that dimension.), and
- (If X and Y are strings) X and Y have S-Equal xml:lang attributes_
Duplicate facts are XML-XBRL syntax valid. However, e.g. EBA Filing Rules don't allow duplicate facts in the XBRL Instance. Duplicate facts can be detected using following snippet:
Dictionary<string, Dictionary<XmlQualifiedName, List<Fact>>> factsByContextKeyAndConceptName = new Dictionary<string, Dictionary<XmlQualifiedName, List<Fact>>>();
Dictionary<string, string> duplicates = new Dictionary<string, string>();
if (InstanceDocument == null)
return;
foreach (Fact f in InstanceDocument.XbrlInstances.FactsWithoutTuples)
{
string key = Context.GetContextKey(f.ContextRef);
if (!factsByContextKeyAndConceptName.ContainsKey(key))
factsByContextKeyAndConceptName.Add(key, new Dictionary<XmlQualifiedName, List<Fact>>());
if (!factsByContextKeyAndConceptName[key].ContainsKey(f.ConceptQName))
factsByContextKeyAndConceptName[key].Add(f.ConceptQName, new List<Fact>());
factsByContextKeyAndConceptName[key][f.ConceptQName].Add(f);
}
StringBuilder sb = new StringBuilder();
int count = 0;
foreach (var context in factsByContextKeyAndConceptName)
foreach (var concept in context.Value)
if (concept.Value.Count > 1)
{
count++;
foreach (var doubles in concept.Value)
{
//tracking down what duplicates are detected
sb.Append(doubles + Environment.NewLine);
//deleting duplicate facts from Instance object
InstanceDocument.XbrlInstances.RemoveFact(doubles);
}
}